[AINews] Test-Time Training, MobileLLM, Lilian Weng on Hallucination (Plus: Turbopuffer) • ButtondownTwitterTwitter
Chapters
AI Model News and Releases
Part 1: High level Discord summaries
Modular (Mojo 🔥) Discord
Examples of Models and Discussions on Discord
Unsloth AI Community Collaboration
CUDA Mode Discussions
Exciting Developments in Modular (Mojo)
LL Studio Development
LlamaIndex General Chat
Discussion on Perplexity AI in Various Channels
LangChain AI Tutorials
Interconnects and AI-related Discussions
AI Model News and Releases
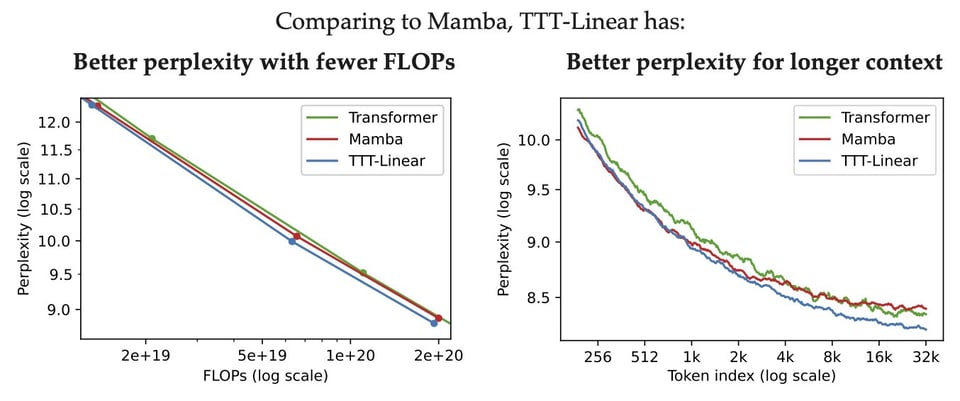
This section provides a recap of the latest news and releases related to AI models and architectures, as well as discussions on AI safety and ethics. It covers various topics such as the open-sourcing of CodeGeeX4-ALL-9B by Tsinghua University, the promising performance of Mamba-Transformer hybrids, the release of the Phi-3 framework for Mac, and concerns raised by ex-OpenAI researcher William Saunders regarding safety neglect in the AI industry. Additionally, an AI model compliance test results in a discussion on censorship variance. This section offers a comprehensive overview of recent developments in the AI field.
Part 1: High level Discord summaries
This section highlights the latest advancements and discussions in the AI community, focusing on various topics such as model advancements, AI research frontiers, AI tooling and deployment advances, ethical AI debates, model performance optimization, generative AI in storytelling, and AI in education. The content covers a wide range of subjects including advancements in model training efficiency, innovative AI research techniques, AI pentesting, generative AI impact on storytelling, and the integration of AI kernels in different platforms. The community engages in discussions about hardware efficiencies, model optimizations, and the ethical implications of AI technology.
Modular (Mojo 🔥) Discord
- Chris Lattner's Anticipated Interview: The Primeagen is set to conduct a much-awaited interview with Chris Lattner on Twitch, sparking excitement and anticipation within the community.
- Eager discussions ensued with helehex teasing a special event involving Lattner tomorrow, further hyping up the Modular community.
- Cutting-Edge Nightly Mojo Released: Mojo Compiler's latest nightly version, 2024.7.905, introduces improvements such as enhanced
memcmpusage and refined parameter inference for conditional conformances.- Developers keenly examined the changelog and debated the implications of conditional conformance on type composition, particularly focusing on a significant commit.
- Mojo's Python Superpowers Unleashed: Mojo's integration with Python has become a centerpiece of discussion, as documented in the official Mojo documentation, evaluating the potential to harness Python's extensive package ecosystem.
- The conversation transitioned to Mojo potentially becoming a superset of Python, emphasizing the strategic move to empower Mojo with Python's versatility.
- Clock Precision Dilemma: A detailed examination of clock calibration revealed a slight yet critical 1 ns discrepancy when using
_clock_gettimecalls successively, shedding light on the need for high-precision measurements.- This revelation prompted further analysis on the influence of clock inaccuracies, underlining its importance in time-sensitive applications.
- Vectorized Mojo Marathons Trailblaze Performance: Mojo marathons put vectorization to the test, discovering performance variables with different width vectorization where sometimes width 1 outperforms width 2.
- Community members stressed the importance of adapting benchmarks to include both symmetrical and asymmetrical matrices, aligning tests with realistic geo and image processing scenarios.
Examples of Models and Discussions on Discord
This section discusses various examples of models and their functionalities as well as ongoing discussions on Discord channels related to AI and technology. It includes insights on code instruction examples, model executions, adaptive feature enhancements, model robustness, local vision modes, refined generation patterns, synchronized workflow implementations, interpreting screen coordinates, GPU support, tutorials on tinygrad concepts, NV=1 deployment challenges, WSL2 issues, and compatibility questions. It also covers discussions on Copilot disputes, vector vocabularies, Google Flame retractions, performance penalties, multi-GPU speed scenarios, Cohere's CommandR for education, dark mode developments, LLama book-to-game adaptations, information retrieval podcast interviews, performance impacts, Anthropic platform credits, and literature-based game creations.
Unsloth AI Community Collaboration
Albert_lum and Timotheeee1 discuss challenges and solutions related to training custom embeddings and memory consumption in LLaMA 3 models. The development of a Modular Model Spec for AI models is highlighted for increased flexibility and convenience. Additionally, fine-tuning LLaMA 3 for SiteForge, a company specializing in AI-generated web page design, is mentioned with features like an AI Sitemap Generator and drag-and-drop website restructuring.
CUDA Mode Discussions
The CUDA Mode section features various discussions related to integrating Triton kernel with PyTorch models, custom functions registration, CUDA kernel integrations, Tensor offloading, and more. Members explore topics like ring attention for splitting KV cache, exploring flash attention, and integrating MuP library. Additionally, there are talks about the impact of AI on jobs, the Hermes 2 Pro model, challenges in jailbreaking models, and a GIF shared by Gary Marcus and Yann LeCun.
Exciting Developments in Modular (Mojo)
This section discusses various exciting updates and discussions related to Modular (Mojo) programming language. It covers topics such as optimizing Mojo projects, integrating Python modules, language syntax usability, open-sourcing of Mojo standard library, and debate on value vs. reference semantics in Mojo. Additionally, a new nightly update for the Mojo compiler is released, and there are discussions on conditional conformance support and handling Unix FIFO in Mojo. Stay up-to-date with the latest advancements in the Modular (Mojo) community!
LL Studio Development
- Disable GPU Offload to Resolve Issues: A user suggested disabling GPU offload to resolve potential issues.
- Long Context Handling Issues on Linux: Users reported difficulty with long contexts on Linux, contrasting with Windows experiences.
- Prompt to Report Bugs in Correct Channel: New users were directed to the bug reports channel for issue resolution.
- Extra RAM Needed for Full Context Length: Users noted the need for additional RAM to accommodate full context lengths, particularly on Linux setups.
LlamaIndex General Chat
The general chat in LlamaIndex covers various topics related to AI development and troubleshooting:
- Enhancing E-commerce RAG chatbot by adding follow-up question capabilities for project queries.
- Troubleshooting import errors with FlagEmbeddingReranker and resolving it by installing 'peft' separately.
- Discussions on rate limit issues with Groq API and potential associations with OpenAI's default embedding models.
- Seeking advice on managing large datasets in chatbots derived from PDFs and recommendations for loaders, chunking strategies, and vector databases.
- Troubles with implementing astream_chat in LlamaIndex due to asyncio method errors.
Discussion on Perplexity AI in Various Channels
- General chat on Perplexity AI features includes concerns about streaming issues with the async generator in a Server Side Event setup. Suggestions for alternative tools like Arc Search were shared along with experiences related to contextual understanding and API credit usage.
- Topics covered in different Perplexity AI channels encompass discussions on the platform's features like context handling for Perplexity, integration possibilities with tools like Notion, and comparisons between different versions of AI models like Claude and Gemini.
- LAION research findings delve into exploring complex-valued architectures and their performance on CIFAR-100, along with the release of the first generative chameleon model. Discussions on copyright laws and practical applications of AI systems were also part of the discourse.
- Resources shared in the LAION channel include educational materials on image diffusion models and discussions on training challenges faced with varying levels of model scaling.
- OpenRouter community experiences cover issues like quota limits, model integration challenges, and image viewing issues on models like gpt-4o and firellava13b. The effectiveness of LLMs for language translation was also discussed.
LangChain AI Tutorials
Learning tinygrad with video courses:
A member asked for video course recommendations for learning tinygrad and was advised to watch Karpathy's transformer video despite it being in PyTorch as it engages viewers better.
"Thanks a lot Tobi.. I will try that.. probably a good way to explore documentation while implementing it." - ghost22111
- Issues with NV=1 on WSL2: A member experienced issues getting NV=1 working on WSL2 and found dev/nvidiactl to be missing, with some suggestions pointing to dxg.
Interconnects and AI-related Discussions
This section covers various discussions related to interconnects, GitHub Copilot lawsuit, AI bill controversy, multi-GPU training issues, realistic performance expectations, Cohere's teaching platform, dark mode release, KAN paper discussions, and information retrieval experts for a podcast series.
FAQ
Q: What is Python's integration with Mojo discussed in the essai?
A: The essai mentions Mojo's integration with Python, exploring the potential to leverage Python's extensive package ecosystem and the possibility of Mojo becoming a superset of Python for added versatility.
Q: What performance variables were discovered when testing Mojo marathons in the essai?
A: Community members found that Mojo marathons testing vectorization performance revealed scenarios where width 1 sometimes outperforms width 2, emphasizing the importance of including benchmarks for both symmetrical and asymmetrical matrices.
Q: What issues were reported by users on Linux in the essai related to long contexts?
A: Users reported difficulties with long contexts on Linux setups compared to Windows experiences, highlighting the need for extra RAM to handle full context lengths effectively.
Q: What topics were discussed in the LlamaIndex general chat related to AI development and troubleshooting in the essai?
A: The LlamaIndex general chat covered topics such as enhancing an E-commerce RAG chatbot, troubleshooting import errors with FlagEmbeddingReranker, dealing with rate limit issues with Groq API, managing large datasets from PDFs in chatbots, and troubles with implementing astream_chat due to asyncio method errors.
Q: What community experiences were shared in the OpenRouter community in the essai?
A: The OpenRouter community shared experiences related to quota limits, model integration challenges, and image viewing issues with models like gpt-4o and firellava13b. Additionally, discussions on the effectiveness of LLMs for language translation took place.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!