[AINews] Miqu confirmed to be an early Mistral-medium checkpoint • ButtondownTwitterTwitter
Chapters
Discord Summary
Eleuther Discord Summary
Latent Space Discord Summary
LM Studio Models Discussion Chat
LM Studio Feedback and Hardware Discussion
HuggingFace Discord General Chat
HuggingFace Community Updates
Diverse Discussions in AI Communities
LLM Perf Enthusiasts AI
Efficient LVLMs and Multilingual Text-to-Image Benchmark
Guide to Submit Projects
Discord Summary
TheBloke Discord Summary
- Engineers are discussing the Miqu model and comparing it to other models like Llama-2-70B and Mixtral, focusing on tasks like instructions and critiques.
- Developers are sharing insights on optimal browsers, UI aesthetics, and niche browser choices like Vivaldi and Docker on Ubuntu systems.
- Users are exploring creative uses of chat models for role-playing scenarios and discussing models for fine-tuning and coding practices.
Nous Research AI Discord Summary
- The Activation Beacon method is changing LLM's memory consumption management by allowing models to generalize to 400K contexts with linear inference time growth.
- SQLCoder-70B is excelling in Postgres text-to-SQL conversion, offering new standards in SQL generation.
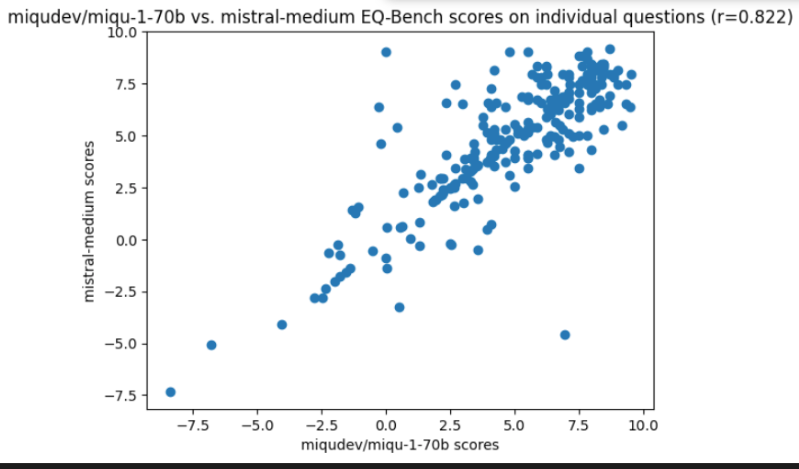
- The Miqu model has outperformed previous benchmarks, scoring 83.5 on EQ-Bench, sparking discussions on its capabilities.
LM Studio Discord Summary
- LM Studio users resolved API connection issues, explored text-to-video puppeteering, and shared GPU acceleration optimizations.
- Discussions covered compatibility challenges across different hardware and emerging trends in AI model performance.
OpenAI Discord Summary
- Discussions revolve around VRAM choices for AI beginners, limits in GPT Plus, and the introduction of GPT mentions for enhanced AI composability.
- Challenges in managing GPT in word games and the integration of DALL-E 3 and GPT for text and visual generation projects were highlighted.
- Community members are troubleshooting API complexities and limitations for multi-step processes and project workflows.
Eleuther Discord Summary
- Ratchet Revolutionizes ML in Browsers: Ratchet, a novel ML framework for browsers, promises optimized speed and developer experience using Rust and WebGPU, showcased in whisper-turbo.com.
- EleutherAI's Research Triumph: Celebrates the acceptance of 6 out of 10 papers at ICLR, achieving advancements like "LLeMA: An Open Language Model for Mathematics".
- Sparse Fine-Tuning Outshines LoRA: Introduces a new method for sparse fine-tuning large language models, potentially revolutionizing instruction tuning.
- CUDA and CUDNN on PPC64LE Present Challenges: Documenting difficulties faced in optimizing AI development environments on specific architectures.
- Tokenizing Strokes for Vector Graphic Synthesis: StrokeNUWA introduces a method for tokenizing strokes to facilitate vector graphic synthesis.
Latent Space Discord Summary
VFX Studios Eye AI Integration:
- Major VFX studios, including one owned by Netflix, seek professionals skilled in stable diffusion technologies, highlighting the rising importance of generative imaging and machine learning in storytelling revolution. A job listing from Eyeline Studios reaffirms this trend.
New Paradigms in AI Job Requirements Emerge:
- AI technologies like Stable Diffusion and Midjourney are humorously predicted to become typical job demands, signaling a shift in tech employment standards.
Efficiency Breakthroughs in LLM Training:
- A new paper by Quentin Anthony suggests hardware-utilization optimization during transformer model training, aiming to tackle inefficiencies in the process.
Codeium's Leap to Series B Funding:
- Codeium's advancement to Series B funding is celebrated, reflecting optimism and growth in the company's future.
Hardware-Aware Design Boosts LLM Speed:
- A hardware-aware design tweak yields a 20% throughput improvement for 2.7B parameter LLMs, showcasing overlooked advancements beyond GPT-3's architecture.
Treasure Trove of AI and NLP Knowledge Unveiled:
- @ivanleomk shares a curated list of landmark AI and NLP resources, offering a comprehensive starting point for exploration in the field.
LM Studio Models Discussion Chat
Tiny Models Go Absurd After Reboot:
- <code>@pudlo</code> reported that highly quantized tiny models, after a reboot, started producing hilariously absurd jokes, making them unintentionally funny.
Suggestion for a "Top Models of the Month" Channel:
- <code>@666siegfried666</code> proposed creating a channel to highlight top models of the month, sparking a lively discussion on how to make model recommendations more accessible and organized. Suggestions included voting systems and admin-only posting to ensure readability.
Challenges with CodeLlama 70B Model:
- Multiple users, including <code>@unskilless</code> and <code>@dave000000</code>, reported problems with the CodeLlama 70B model, noting it was "terribly broken" for specific tasks. However, <code>@heyitsyorkie</code> suggested using the "Codellama Instruct" preset for better results.
LM Studio Feedback and Hardware Discussion
LM Studio Feedback:
- Model Compatibility Confusion Cleared: @rasydev faced an error when loading a model in LM Studio, clarified by @heyitsyorkie that LMStudio is only compatible with GGUF models.
- CodeLlama Models Misunderstanding: CodeLlama models do not work with LMStudio by default as they are RAW PyTorch models; recommendation to search for GGUF quants for compatibility.
LM Studio Hardware Discussion:
- Retro Tech in Modern Train Systems: German railway automation operates on MSDOS and Windows 3.1, sparking discussions on the efficiency of older systems for specific applications.
- Performance Insights on Minimal Tech: Discussions on efficient use of minimal hardware like 125MHz, 8MB RAM for specific applications, showcasing the continuous effectiveness of seemingly outdated hardware.
- AI and Gaming Evolving Together: Speculation on future intersection of AI and gaming, from AI NPCs to games generated on-the-fly by AI, highlighting the enthusiasm for AI's potential in game development.
- Hardware and AI Development Constraints: Touching on running large language models, importance of GPU over RAM for speed, multi-GPU setups for gaming tasks and hardware designed for AI acceleration.
- Navigating the Best Hardware Setup for AI Applications: Debate on investing in high powered GPUs versus ample RAM for AI models, leaning towards advanced GPUs for significant performance gains.
HuggingFace Discord General Chat
The HuggingFace Discord General Chat consists of discussions on various topics related to LLMs (Large Language Models) and multimodality. Users are exploring how models handle multiple images and videos for context understanding, with an interest in LLMs that have 3D understanding. Practical experiences and surveys on these topics are being sought after.
HuggingFace Community Updates
This section provides updates and discussions from the HuggingFace community. It includes the unveiling of a multimodal Malaysian LLM dataset hosted on HuggingFace, a Gradio app for transforming Excel/CSV files into database tables, discussions on Twitter posts for ML projects, CUDA memory allocation inquiry, running TTS AI on low-spec hardware, Excel to database transformation, AI existential fears, Magic: The Gathering model, and more. The section showcases collaborations, model developments, hardware discussions, and community queries across various AI-related topics.
Diverse Discussions in AI Communities
In this series of conversations within AI communities, various topics were discussed. These include potential problems with Docker mounting in workspace directories, warnings about deprecated Jupyter server extension functions, inquiries about Mistral Medium API access, confusion over free trials in Perplexity AI, and discussions on utilizing Perplexity for creative content generation. Additionally, there were talks about using Cody, a free AI coding assistant, local model training options, troubleshooting API authentication errors, and improving CUDA performance. Links to valuable resources and tools were also shared throughout the discussions.
LLM Perf Enthusiasts AI
LLM Perf Enthusiasts AI
- CUDA Memory Indexing Explained: @andreaskoepf detailed how to calculate the memory index in CUDA, emphasizing the roles of
blockDim.x,blockIdx.x, andthreadIdx.xin determining an element's index within a specific section of the memory array. - Understanding Through Collaboration: Following an explanation from @andreaskoepf, @ashpun expressed gratitude for the clarity provided on CUDA memory indexing, highlighting the value of community support in resolving technical inquiries.
- Exploring CUDA Events for Timing: @shindeirou initiated a discussion on the necessity of using
cudaEventSynchronize()when measuring the time ofcudaMemcpyoperations, despite the blocking nature ofcudaMemcpy. - Clarifying CUDA Timing Mechanisms: @tvi responded to @shindeirou with a clarification that synchronization is needed for both the completion of
cudaMemcpyoperations and the recording of the event itself, which might explain unexpected behavior like getting 0.0 in timing measurements. - Importance of Synchronization in CUDA: @vim410 emphasized that all CUDA API calls should be considered asynchronous by default, underscoring the importance of explicit synchronization when capturing performance metrics.
Efficient LVLMs and Multilingual Text-to-Image Benchmark
Introducing MoE-LLaVA for Efficient LVLMs: @nodja shared a paper on arXiv introducing MoE-tuning and the MoE-LLaVA framework, aimed at improving Large Vision-Language Models (LVLMs) efficiency by activating only the top-k experts during deployment. This strategy enables the construction of sparse models with a high number of parameters but constant computational cost.
MoE-LLaVA Demonstrated on Hugging Face: Follow-up, @nodja also highlighted the MoE-LLaVA model's implementation on Hugging Face's platform, inviting the community for direct exploration.
MAGBIG: A New Multilingual Text-to-Image Benchmark: @felfri_ shared MAGBIG, a newly proposed benchmark for evaluating multilingual text-to-image models, encouraging the community to use and share it. This dataset aims to advance the development and assessment of models on a broader linguistic scale.
Guide to Submit Projects
A Guide to Submit Projects to AI Engineer Foundation was shared for interested parties. The link provided directs to the guide document. Don't miss subscribing to AI News for further updates.
FAQ
Q: What are some of the models discussed in TheBloke Discord Summary?
A: Some of the models discussed include Miqu, Llama-2-70B, Mixtral, Activation Beacon method, SQLCoder-70B, CodeLlama 70B, LLeMA, CUDA, CUDNN, StrokeNUWA, and Ratchet.
Q: What is the significance of the Miqu model?
A: The Miqu model has outperformed previous benchmarks, scoring 83.5 on EQ-Bench, sparking discussions on its capabilities and potential advancements in the field.
Q: What is the focus of discussions in the LM Studio Discord Summary?
A: Discussions in LM Studio cover topics such as resolving API connection issues, text-to-video puppeteering, GPU acceleration optimizations, hardware compatibility, and emerging trends in AI model performance.
Q: What hardware challenges are discussed in the OpenAI Discord Summary?
A: Discussions in OpenAI revolve around VRAM choices for AI beginners, challenges in managing GPT Plus, CUDA and CUDNN optimization on PPC64LE, and the integration of DALL-E 3 and GPT for text and visual generation projects.
Q: What new advancements were celebrated in the AI community according to the provided summaries?
A: Advancements such as Sparse Fine-Tuning Outshining LoRA, EleutherAI's acceptance of 6 out of 10 papers at ICLR, Ratchet revolutionizing ML in browsers, and Codeium's leap to Series B funding were celebrated.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!