[AINews] Hybrid SSM/Transformers > Pure SSMs/Pure Transformers • ButtondownTwitterTwitter
Chapters
AI Twitter Recap
AI Discord Recap
LangGraph and Nous Research AI Discord
Latent Space Discord
Unsloth AI (Daniel Han) and Help
Hooting Problems
LLM Finetuning with Hamel and Dan
Nous Research AI ▷ #interesting-links
CUDA Mode Torch
Eleuther Discord Discussion
LangChain AI Community Updates
OpenInterpreter ▷ #general (40 messages🔥):
Subscription and Social Networks
AI Twitter Recap
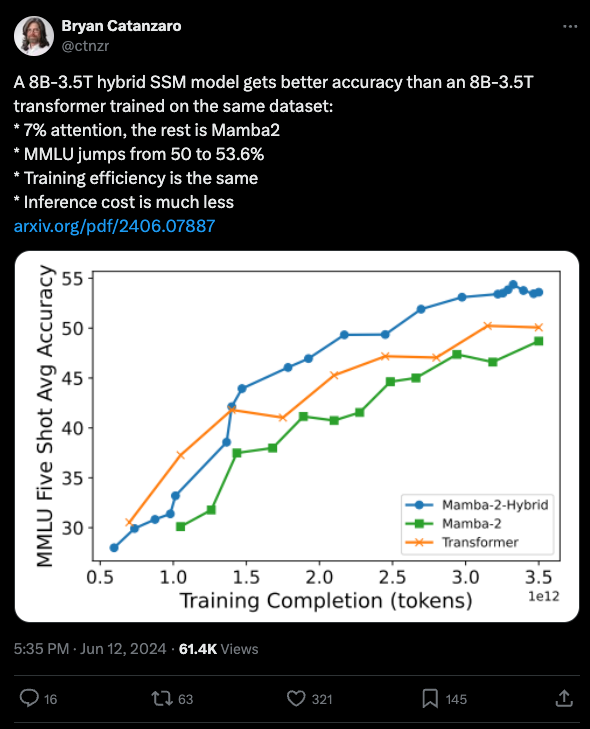
The AI Twitter Recap section highlights various updates and discussions from the AI community on Twitter. Some key points include: - The use of Mixture-of-Agents (MoA) to enhance LLM performance, scoring 65.1% on AlpacaEval 2.0 - Introduction of LiveBench AI benchmark for LLM evaluation - Hybrid SSM model outperforming Transformers with 7% attention - GPT-4's performance at different temperatures - Qwen 72B as a leading open-source model - Memory tuning with Mixture-of-Experts for improved accuracy - Sakana AI Lab's evolutionary LLM optimization approach.
AI Discord Recap
Stable Diffusion 3 Faces Scrutiny but Offers Alternatives:
- SD3 Faces Criticism for Model Quality: Users conveyed dissatisfaction with SD3—highlighting anatomical inaccuracies and prompt issues—while medium models can be downloaded on Huggingface.
- Preferred Interfaces & Tools Discussed: ComfyUI emerged as the favored interface, with suggested samplers like uni_pc and ddim_uniform for optimal performance. Alternatives like Juggernaut Reborn and Playground are highlighted for their specific capabilities.
Boosting AI Performance and Infrastructure Insights:
- LLM Performance Boosted by Higher Model Rank: Shifting from rank 16 to 128 resolved Qwen2-1.5b's gibberish output, aligning it with llama-3 caliber outputs.
- Perplexity AI's Efficient LLM Use: Quick results are achieved by leveraging NVIDIA A100 GPUs, AWS p4d instances, and TensorRT-LLM optimizations.
Innovations in Fine-Tuning and Quantization:
- Fine-Tuning LLMs with New Models: The discussion covered the legal aspects of using GPT-generated data, referencing OpenAI's business terms. Experimentations with ToolkenGPT show creative approaches to synthetic data for fine-tuning.
- CUDA Quantization Project discussions: Projects like the BiLLM showcase rapid quantization of large models, essential for efficient AI deployments.
Model Management and Deployment Techniques:
- Strategies for Handling Large Embeddings: Queries about 170,000 embedding indexes led to recommendations on using Qdrant or FAISS for faster retrieval. Specific fixes for erroneous queries were shared here.
- Docker and GPU Configuration Troubleshooting: Users dealing with Docker GPU detection on WSL found solutions by consulting the official NVIDIA toolkit guide.
AI Community Trends and Updates:
- OpenAI's Revenue Milestone and Focus Shift: OpenAI's revenue doubled, reflecting sales direct from ChatGPT and other services, not primarily facilitated by Microsoft (source).
- Partnerships and Conferences Engage Community: Aleph Alpha and Silo AI joined forces to advance European AI (read more), and Qwak's free virtual conference promises deep dives into AI mechanisms and networking opportunities.
LangGraph and Nous Research AI Discord
LangGraph has sparked diverse opinions with its introduction prompting discussions about function execution capabilities in models. In the Nous Research AI Discord, a paper on arXiv details a method for discovering optimization algorithms for large language models driven by the models themselves. Additionally, a Mixture-of-Agents architecture shows promising performance surpassing GPT-4 Omni. Stable Diffusion 3 receives both applause and criticism, while there is ongoing development on the RAG dataset schema and discussions around GPT-4's performance configurations. The community is also actively engaged in sharing knowledge and insights related to advanced AI models and projects.
Latent Space Discord
Open Interpreter Empowers LLMs
Open Interpreter is being discussed as a means to transform natural language into direct computer control, offering a bridge to future integrations with tailored LLMs and enhanced sensory models.
Vision Meets Code in Practical Applications
The community shared experiences and troubleshooting tips on running code alongside vision models using Open Interpreter, particularly focusing on the llama3-vision.py profile, and strategies for managing server load during complex tasks.
Browser Control Scores a Goal
A real-world application saw Open Interpreter successfully navigating a browser to check live sports scores, showcasing the simplicity of user prompts and the implications on server demand.
DIY Approach to Whisper STT
While seeking a suitable Whisper Speech-To-Text (STT) library, a guild member ended up crafting a unique solution themselves, reflecting the community's problem-solving ethos.
Tweaking for Peak Performance
Discussions on fine-tuning Open Interpreter, such as altering core.py, highlighted the ongoing efforts to address performance and server load challenges to meet the particular needs of users.
Unsloth AI (Daniel Han) and Help
Trainer and TrainingArguments Confusion:
A user expressed confusion about the specifics of Trainer and TrainingArguments in the Huggingface documentation. They noted that the descriptions do not fully explain how to use these classes.
- Saving as gguf Issues:
A user faced a
ValueErrorwhen attempting to save a model as gguf, but found success after specifyingf16as the quantization method. They shared this solution along with the syntax: `model.save_pretrained_gguf("model", tokenizer, quantization_method = "f16"). - Untrained Tokens Error:
Another user encountered a
ValueErrorrelated to untrained tokens while training a model, suggesting thatembed_tokensandlm_headmust be included in the training process. This issue was linked to adding new tokens that require enabling training on certain model parts. - Dataset Formatting for Multilabel Classification: One member sought advice on finetuning Llama 3 for multilabel classification and whether the same prompt format could be used. While responses acknowledged the need for consistent dataset templates, no specific solution for multilabel classification was provided.
- citing Unsloth: Users discussed how to cite Unsloth in a paper, with a suggestion to reference it as: "Daniel Han and Michael Han. 2024. Unsloth, Unsloth AI." followed by the Unsloth GitHub page.
Hooting Problems
Tiny-AI-Client simplifies LLM usage:
- A member introduced a tiny, intuitive client for LLMs that supports vision and tool use, as an alternative to langchain for simpler use cases.
SimpleTuner release integrates SD3:
- A new release of SimpleTuner fully integrates Stable Diffusion 3's unet and lora training.
French Deep Learning Notebooks:
- A GitHub repository containing Deep Learning notebooks in French was shared.
Conceptual Captions dataset:
- A member shared a massive dataset with 22 million high-quality captions for 11 million images from Google's CC12M, created using LLaVaNext.
LLM Finetuning with Hamel and Dan
This section provides updates and discussions related to LLM Finetuning with Hamel and Dan. It includes information on topics such as LangSmith Free Developer Plan details, challenges in category selection approaches, and building new knowledge through fine-tuning models. Members also discuss issues with model weights, the usage of synthetic data for fine-tuning, and special tokens configuration in Axolotl. Additionally, a new Glaive Function Calling model introduction is shared, highlighting its capabilities for multi-turn conversations and intelligent function execution.
Nous Research AI ▷ #interesting-links
LLM-driven objective discovery pushes the boundaries of preference optimization
A paper on arXiv explores offline preference optimization for LLMs using LLM-driven objective discovery to automatically find new optimization algorithms. This approach allows for the discovery of preference optimization algorithms without expert human intervention by iteratively prompting an LLM based on performance metrics.
Mixture-of-Agents (MoA) methodology harnesses multiple LLMs' collective expertise
Another paper on Hugging Face proposes using a Mixture-of-Agents architecture, where multiple LLM agents in layered configurations collaborate to enhance performance on various benchmarks. The MoA model outperforms GPT-4 Omni, achieving a remarkable score of 65.1% on AlpacaEval 2.0 compared to GPT-4 Omni's 57.5%.
GitHub repository for MoA methodology
The implementation of the Mixture-of-Agents model can be found on GitHub. Users can contribute to and explore the development of this promising approach to leveraging multiple LLMs.
CUDA Mode Torch
This section discusses various topics related to CUDA Mode Torch, including discussions on creating a fast 8-bit optimizer with PyTorch, concerns about drop-in replacements for 8-bit optimizers, proposals for a pure PyTorch + Triton version of 8-bit optimizers, and long-term roadmap considerations for integrating bitsandbytes with torch.compile. The section also mentions the potential challenges and benefits of using mixed precision operations like FP16 x FP8, and the limitations posed by Microsoft's BitBLAS implementation. Links mentioned include resources for PyTorch testing, torch_compile experiments, and bitsandbytes implementation details.
Eleuther Discord Discussion
This section provides insights from discussions happening in the Eleuther Discord channels. In one debate, members discussed the use of acc_norm by tokens vs bytes for the same tokenizer. Another topic covered issues with generating content on Qwen1.5-7B-Chat and possible fixes. Additionally, links and discussions related to AI, infrastructure, and models like MoA and CFG++ were shared among the members.
LangChain AI Community Updates
Chain can use string distance metrics or embedding distance metrics to evaluate similarity, with practical code examples provided. The community discussed various topics, such as managing state in LangGraph and handling human intervention in LangChain workflows. Links were shared for evaluating chat bot feedback, migrating from legacy agents to LangGraph, and adding chat history. Additionally, members shared projects like the Tiny AI Client and demonstrated running LLMs locally with Docker. In other channels, discussions ranged from Windows support for Mojo to advancements in language models like Samba 3.8B and hybrid SSM/transformer architectures. The latest news included OpenAI's revenue growth, new AI models, and partnerships in the AI industry.
OpenInterpreter ▷ #general (40 messages🔥):
A discussion around the capabilities of Open Interpreter was detailed, highlighting how it provides agentic power to Large Language Models (LLMs), converting natural language into computer control. The conversation explored running vision models, browser automation examples, performance and customization issues, and the utilization of Whisper STT library. Members also engaged in discussions about Docker Desktop struggles, installing the CUDA toolkit, and configuring WSL 2 and GPU. Links shared included resources on NVIDIA toolkit installation and OpenRouter. The section showcased a vibrant exchange of insights and troubleshooting tips in the OpenInterpreter community.
Subscription and Social Networks
The epilogue section encourages readers to subscribe to AI News. A subscription form is provided for readers to enter their email address and subscribe. Additionally, links to the AI News Twitter and Newsletter are available. The footer section also includes links to the AI News Twitter and Newsletter. The newsletter is brought to you by Buttondown, a platform for starting and growing newsletters.
FAQ
Q: What is Mixture-of-Agents (MoA) and how does it enhance LLM performance?
A: Mixture-of-Agents (MoA) is a methodology where multiple LLM agents in layered configurations collaborate to enhance performance on various benchmarks. It harnesses multiple LLMs' collective expertise and outperforms models like GPT-4 Omni.
Q: What is Stable Diffusion 3 (SD3) and what are some criticisms associated with it?
A: Stable Diffusion 3 (SD3) is a model that has faced criticism for issues related to anatomical inaccuracies and prompt quality. Users have expressed dissatisfaction with SD3's model quality.
Q: How is LLM performance boosted by higher model rank, as mentioned in the AI Twitter Recap?
A: Shifting from rank 16 to 128 has resolved gibberish output issues for models like Qwen2-1.5b, aligning their output with llama-3 caliber results. This change in rank has shown to significantly boost LLM performance.
Q: What are some insights shared about fine-tuning LLMs with new models in the AI community discussion?
A: The discussion covered legal aspects of using GPT-generated data, experimentations with synthetic data for fine-tuning using tools like ToolkenGPT, and the importance of incorporating new models for effective fine-tuning.
Q: How does the Mixture-of-Agents (MoA) model perform compared to GPT-4 Omni according to the AI Twitter Recap?
A: The MoA model surpasses GPT-4 Omni's performance, achieving a remarkable score of 65.1% on AlpacaEval 2.0 compared to GPT-4 Omni's score of 57.5%.
Q: What are some challenges and benefits discussed regarding mixed precision operations as mentioned in the AI community discussions?
A: Challenges and benefits related to using mixed precision operations like FP16 x FP8 were discussed, including concerns about limitations posed by implementations such as Microsoft's BitBLAS, alongside potential benefits for efficiency in AI operations.
Q: How does Open Interpreter empower Large Language Models (LLMs) according to the AI Community Trends and Updates?
A: Open Interpreter provides agentic power to LLMs by transforming natural language into direct computer control. It offers a bridge to future integrations with tailored LLMs and enhanced sensory models.
Q: What are some practical applications discussed where vision meets code using Open Interpreter?
A: Members shared experiences and troubleshooting tips on running code alongside vision models with Open Interpreter. Applications included navigating a browser to check live sports scores, highlighting user prompts simplicity and server demand implications.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!